Data package
The Friendly data format 1 has been designed to facilitate interoperability in a diverse ecosystem by prioritising ease of sharing. A data package includes several datasets, and a description of the datasets that includes metadata and structural information (also known as schema).
The metadata of a dataset typically establishes the context for the dataset. It can consist of properties like:
a computer program friendly name so that they can be referred to easily from software,
a title and free-form description so that other researchers using the dataset are aware of its provenance and can use it correctly,
search keywords for easier discoverability on online platforms,
license information so that others know the terms of use, and
citation information.
And structural information (or schema) includes type information of columns in a dataset, states any constraints, and assumptions implicit in the data.
A data package is a collection of datasets, any related source code,
relevant licenses, and a datapackage.json file that records all
the metadata. This is based on the widely recognised frictionless
standard; further details can be found on the frictionless
documentation page.
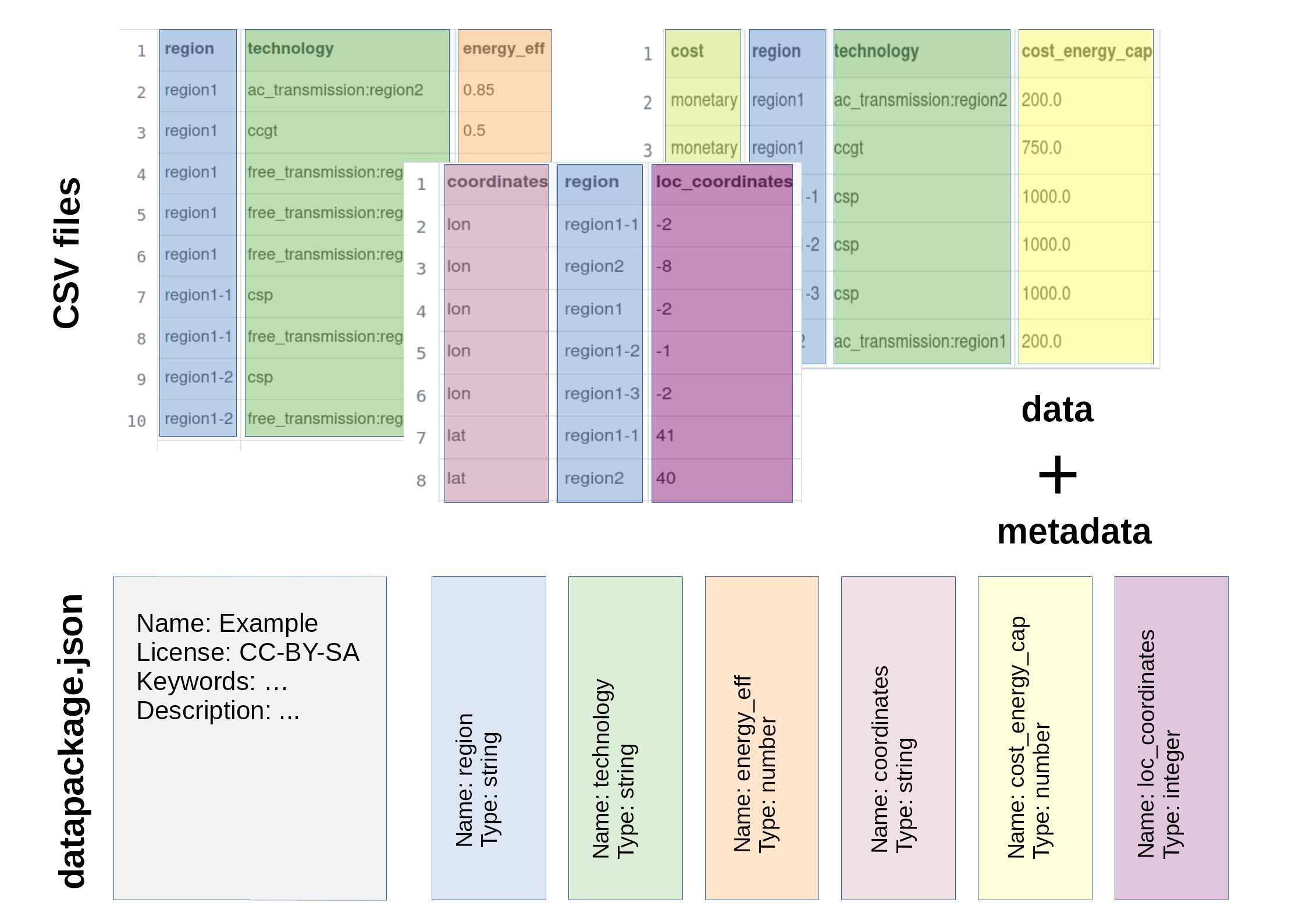
A typical data package consists of a collection of datasets,
e.g. CSV files, and related metadata in the datapackage.json
files. There are two kinds of metadata: a) package wide semantic
information providing context, terms of use, etc, and b) structural
information (or schema), e.g. column names and types.
The figure above is a graphical depiction of a data package. The
three tables are three separate datasets stored in CSV files. And the
metadata in the accompanying datapackage.json file include
semantic metadata like name, title, description, license, keywords,
etc, and schema of all the columns present in the CSV files; e.g. here
you can see region, technology, are strings, but
energy_eff is a number. Each dataset has an entry in the metadata
file, which states its name, relative path, and structure (or
schema) of the table. Structural information includes column names,
the type of data stored in each column (number, integer, string, etc),
instructions on how to identify missing values, or how to uniquely
identify each row in a dataset (otherwise known as the “primary key”).
Comprehensive documentation of all possibilities can be found in the
table schema section of the frictionless documentation 2.
Creating a data package manually can be tedious, so the developers of the frictionless specification maintain a web-based user interface (web UI). While it can be used for smaller or simpler data packages, it is not aware of any energy modelling specific terminology or conventions. The web UI is meant to be easy to use, and requires no knowledge of programming.
Friendly data conforms to this specification, however it adds a few energy modelling specific conventions designed to facilitate interoperation between various models. You can either use the command line interface (CLI) or the Python API to create or manage Friendly data packages. While the underlying Frictionless specification provides alternate implementations of the data package format in other programming languages, Friendly data is only available in Python. However, since the underlying design uses established file formats, e.g. using JSON for metadata, and CSV for dataset; there is no barrier to reading a data package in other languages.